A magia do purrr
Você já ouviu falar sobre um pacote de R chamado purrr? Ele é descrito como um toolkit
de programação funcional para a linguagem R e permite que façamos coisas honestamente
incríveis. Se você nunca ouviu falar sobre o purrr ou mesmo se já ouviu falar mas não
sabe de todo o seu potencial, esse post é feito para você.
Perdão pela honestidade
Se você quisesse tornar o R mais conciso, o que você mudaria nele? Uma boa primeira tentativa talvez envolvesse simplificar a “composição de funções” (o ato de aplicar uma função ao resultado de outra). Dê uma olhada nesse exemplo horrível:
car_data <-
transform(aggregate(. ~ cyl,
data = subset(mtcars, hp > 100),
FUN = function(x) round(mean(x, 2))),
kpl = mpg*0.4251)Se não quisermos salvar resultados intermediários, compor diversas funções passa a ser super importante. Mas a estratégia mostrada acima faz com que seja muito difícil entender o que está acontecendo e em que ordem (para os nerds lendo isso, é o equivalente de escrever ao invés de ). Em R, a solução para esse problema vem na forma do “pipe”, um operador que nos permite colocar a primeira função antes da segunda e não dentro dela:
car_data <-
mtcars %>%
subset(hp > 100) %>%
aggregate(. ~ cyl, data = ., FUN = . %>% mean %>% round(2)) %>%
transform(kpl = mpg %>% multiply_by(0.4251))Mas o que mais você mudaria no R? Bem, o próximo lugar que evidentemente precisa de uma melhoria são só laços…
Listas de listas
Antes de começarmos a demonstração, você vai precisar de alguns pacotes. Instale-os rodando o código abaixo:
install.packages(c("devtools", "purrrr"))
devtools::install_github("jennybc/repurrrsive")
library(purrr)Agora que temos tudo pronto, vamos conhecer melhor a estrela desse tutorial! gh_repos
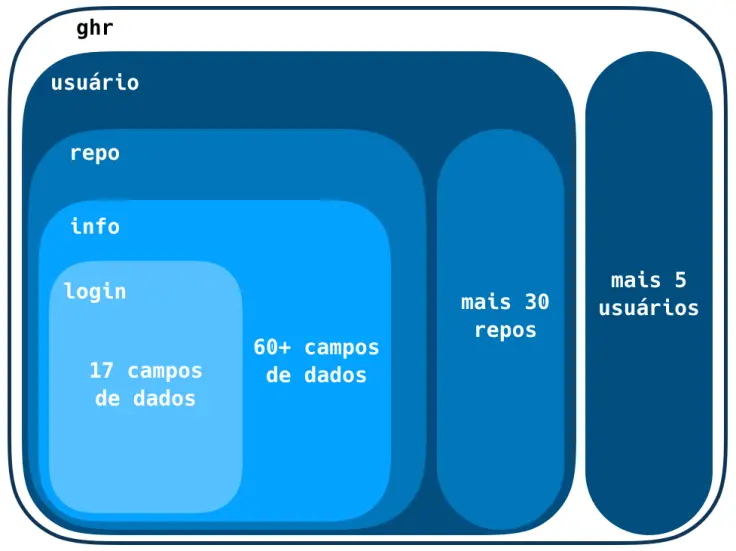
é uma lista multi-nível gigantesca que pode assustar até os programadores de R mais
experientes. Eu vou renomear gh_repos para ghr por simplicidade:
ghr <- repurrrsive::gh_reposFelizmente a sua estrutura é simples o suficiente para que possamos usá-la para
propósitos educacionais. O primeiro nível de ghr é composto por 6 listas, cada uma
representando um usuário do GitHub. Cada uma destas listas é feita de mais ou menos
30 listas menores representando os repositórios daquele usuário. Cada repositório
tem mais de 60 campos com informações sobre o repo; um destes campos também é uma
lista e contém dados de login pertencentes ao dono do repo.
Eu sei que isso não parece muito fácil de entender, mas vamos revisar a estrutura
algumas vezes ainda. Antes de tudo vamos só refrescar as nossas habilidades com listas
e descobrir quantos repositórios o primeiro usuário em ghr tem:
length(ghr[[1]])
# [1] 30Nesse pequeno comando estamos selecionando o primeiro elemento do primeiro nível da lista
(ghr[[1]]) ou, em outras palavras, estamos escolhendo o primeiro usuário. Ao aplicar
length() neste usuário, podemos ver quantos elementos ele(a) tem, resultando no número
de repositórios pertencentes a ele(a). De forma geral, se quiséssemos ver quantos campos
de informação tem o terceiro repo deste usuário (ou o comprimento do terceiro elemento
do segundo nível associado ao primeiro elemento do primeiro nível), poderíamos rodar
length(ghr[[1]][[3]]).
Laços de uma linha
Agora que você se lembra de como listas funcionam em R, um óbvio incremento de dificuldade
é descobrir quantos repositórios cada usuário tem. Isso pode ser resolvido com o bom e
velho laço for, aplicando length() a cada elemento do primeiro nível de ghr:
lengths <- c()
for (i in seq_along(ghr)) {
lengths <- c(lengths, length(ghr[[i]]))
}
lengths
# [1] 30 30 30 26 30 30Mas vamos com calma, tem que existir um jeito mais fácil! Só estamos iterando em uma lista,
por que precisamos de i, c(), seq_along(), ou mesmo lengths? É aqui que o map()
entra em jogo, o carro chefe do pacote purrr. map() é uma abstração de laços, permitindo
que iteremos nos elementos de uma lista e não em alguma variável auxiliar. Em outras
palavras ele aplica uma função em todo elemento de uma lista.
map(ghr, length)
# [[1]]
# [1] 30
#
# [[2]]
# [1] 30
#
# [[3]]
# [1] 30
#
# [[4]]
# [1] 26
#
# [[5]]
# [1] 30
#
# [[6]]
# [1] 30Bem, usamos menos linhas de código, mas o que está acontecendo com essa saída? map() é
uma função muito genérica, então ela sempre retorna listas (assim ela não precisa se
preocupar com o tipo da saída). Mas map() tem várias funções irmãs, map_xxx()
(map_dbl(), map_chr(), map_lgl(), …), que são capazes de “nivelar” a saída
se você já souber que tipo ela terá. No nosso caso queremos um vetor de doubles,
então usamos map_dbl():
map_dbl(ghr, length)
# [1] 30 30 30 26 30 30Você viu isso?! São apenas 21 caracteres e eles fizeram a mesma coisa que aquele laço horrível lá em cima!
Fórmulas e funções
Agora que você já conheceu os princípios fundamentais do purrr, eu vou lhe
apresentar às funções anônimas, outra funcionalidade interessantíssima do pacote.
Elas são funções que podemos definir dentro de um map() sem ter que nomeá-las,
aparecendo em duas formas: fórmulas e funções.
Fórmulas são antecedidas por um til e você não pode controlar o nome de seus argumentos. Funções por outro lado são, bem, funções normais do R. Primeiramente vamos ver como fórmulas funcionam:
map_dbl(ghr, ~length(.x))
# [1] 30 30 30 26 30 30Fórmulas nos permitem passar argumentos para a função sendo mapeada. Lembre-se
de como estamos tirando o comprimento de cada sub-lista de ghr? Se usarmos
a notação-til podemos explicitamente acessar aquele elemento e colocá-lo onde
quisermos dentro da chamada da função, mas o seu nome será .x independentemente
de qualquer outra coisa.
map(1:3, ~runif(2, max = .x))
# [[1]]
# [1] 0.2512402 0.4499058
#
# [[2]]
# [1] 1.767479 1.600513
#
# [[3]]
# [1] 2.367293 1.263795No exemplo acima temos que usar a notação-til porque, se não tivéssemos, o vetor
1:3 acabaria sendo usado como o primeiro argumento de runif(). E falando em
argumentos, map() convenientemente permite que você envie qualquer outro
argumento fixo no final da chamada (note como desta vez 1:3 é usado
automaticamente como o primeiro argumento).
map(1:3, runif, min = 3, max = 6)
# [[1]]
# [1] 3.902211
#
# [[2]]
# [1] 4.511896 4.405196
#
# [[3]]
# [1] 5.498137 3.940454 5.413348E por último mas não menos importante, funções. Elas são muito parecidas com fórmulas, entretanto aqui você pode nomear os argumentos como quiser (a desvantagem é que você tem que definir a função de forma bastante prolixa):
map(1:3, function(n) { runif(n, min = 3, max = 6) })
# [[1]]
# [1] 4.54061
#
# [[2]]
# [1] 3.557612 4.022569
#
# [[3]]
# [1] 3.369300 4.109919 4.095583Maps e maps
Como você já deve ter percebido, também é possível chamar uma map() dentro
da outra! Isso é muito útil quando queremos acessar níveis mais profundos de
uma lista (como quando falamos sobre length(ghr[[1]][[3]])). Vamos ver quantos
campos de informação tem cada repo de cada usuário:
map(ghr, ~map(.x, length))
# [[1]]
# [[1]][[1]]
# [1] 68
#
# [[1]][[2]]
# [1] 68
#
# [[1]][[3]]
# [1] 68
#
# [[1]][[4]]
# [1] 68
#
# ...
map(ghr, ~map_dbl(.x, length))
# [[1]]
# [1] 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68
# [20] 68 68 68 68 68 68 68 68 68 68 68
#
# [[2]]
# [1] 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68
# [20] 68 68 68 68 68 68 68 68 68 68 68
#
# ...O primeiro comando acima devolve uma lista de listas muito longas, mas isso
se deve somente ao fato de que o map() mais interior retorna uma lista
para cada repo e depois o map() mais de fora embrulha tudo aquilo em outra
lista. Para uma saída mais inteligente, usar map_dbl() na chamada mais
interna nos permite devolver um único vetor para cada usuário.
No entanto, esse campos contém outras informações preciosas. Até agora nossa lista
permaneceu completamente sem nomes, o que significa que cada lista de usuário
e cada lista de repo não estão marcadas com os nomes dos usuários e repos. Vamos
ver se podemos encontrar os nomes dos usuários no campo login da lista $owner
de cada repo (note o uso de map_chr(); esse é o equivalente de map_dbl()
para caracteres):
map(ghr, function(user) {
map_chr(user, ~.x$owner$login)
})
# [[1]]
# [1] "gaborcsardi" "gaborcsardi" "gaborcsardi" "gaborcsardi"
# [5] "gaborcsardi" "gaborcsardi" "gaborcsardi" "gaborcsardi"
# ...
#
# [[2]]
# [1] "jennybc" "jennybc" "jennybc" "jennybc" "jennybc"
# [6] "jennybc" "jennybc" "jennybc" "jennybc" "jennybc"
# ...
#
# ...
map(ghr, function(user) {
user %>% map_chr(~.x$owner$login)
})
# ...
map(ghr, ~map_chr(.x, ~.x$owner$login))
# ...Todos os 3 comandos devolvem exatamente a mesma coisa, mas o primeiro é o
mais fácil de entender. Para cada autor, iteramos em seus repos e acessamos
o elemento $owner$login. O segundo nos mostra que é possível mapear um pipe.
O terceiro por sua vez condensa tudo ao máximo (note como usamos .x duas
vezes; a primeira vez vem do map() e representa cada usuário, enquanto a
segunda vem do map_chr() e representa cada repo).
No entanto, todos todos os comandos sofrem de repetição na saída dado que
estamos fazendo a mesma coisa para cada repo disponível. Já que só precisamos
dessa informação uma vez para cada usuário, podemos usar o bom e velho [1]
para pegar apenas o primeiro elemento do vetor retornado por map_chr()
e depois usar outro map_chr() para que não precisemos lidar com listas
estranhas:
map_chr(ghr, ~map_chr(.x, ~.x$owner$login)[1])
# [1] "gaborcsardi" "jennybc" "jtleek" "juliasilge"
# [5] "leeper" "masalmon"Pipes e maps
Na seção acima usamos map()s com pipes, e agora vamos usar pipes
com map()s. Isso deveria ser bastante lógico dado o último trecho
de código, mas vamos usar o map() para pegar o login dos usuários,
usar set_names() para dar nomes aos usuários de acordo com seus
logins e por fim usar pluck() para selecionar a lista de repositórios
de “jennybc” (note o ponto em set_names(); ele representa o resultado
vindo da linha cima, estamos usando ele como o segundo argumento da
função):
ghr %>%
map_chr(~map_chr(.x, ~.x$owner$login)[1]) %>%
set_names(ghr, .) %>%
pluck("jennybc")
# ...A saída desse comando foi omitida, mas usando pluck() selecionamos
apenas o elemento de ghr chamado “jennybc” (essa função trabalha
exatamente como [[]], então poderíamos ter usado 2 já que a lista
de Jenny é a segunda do primeiro nível).
E assim por diante…
Agora que sabemos nomear o primeiro nível da estrutura, que tal fazermos o mesmo para os repos? Para isso precisamos ir um nível mais fundo e colocar nomes lá também:
ghr %>%
map(function(user) {
user %>%
set_names(map(., ~.x$name))
}) %>%
pluck("jennybc", "eigencoder")
# ...
ghr %>%
map(~set_names(.x, map(.x, ~.x$name))) %>%
pluck("jennybc", "eigencoder")
# ...As duas sequencias devolvem a mesma coisa (omitida), mas a segunda é
muito mais concisa. Aqui estamos iterando nos usuários, nomeando cada
repo de acordo com o elemento $name de cada um e por fim selecionando
o repositório eigencoder de Jenny (que seria equivalente a [[2]][[30]]).
Dois coelhos
O legal de programar é tentar escrever a mesma coisa no mínimo de caracteres possível (tarefa apelidada de code golf). Antes de nomearmos tanto usuários e repos, vamos deixar o processo de nomear usuários seja um pouco mais enxuto:
set_names(ghr, map_chr(ghr, ~map_chr(.x, ~.x$owner$login)[1]))
set_names(ghr, map(ghr, ~map(.x, ~.x$owner$login)[[1]]))
set_names(ghr, map(ghr, ~.x[[1]]$owner$login))Todos os 3 comandos fazem a mesma coisa, sendo que já vimos o primeiro antes.
O segundo comando aproveita-se do fato de que set_names() não precisa
receber um vetor como argumento, uma lista também funciona. O terceiro
inverte a ideia de pegar o login de todos os repos e depois selecionar o primeiro
pegando o login apenas do primeiro repo.
Agora que temos a forma mais curta possível de nomear os elementos principais
de ghr, aqui está o que eu chamo de dois coelhos em uma cajadada:
ghr <- ghr %>%
set_names(map(., ~.x[[1]]$owner$login)) %>%
map(~set_names(.x, map(.x, ~.x$name)))
> names(ghr)
# [1] "gaborcsardi" "jennybc" "jtleek" "juliasilge"
# [5] "leeper" "masalmon"
> names(ghr$jennybc)
# [1] "2013-11_sfu"
# [2] "2014-01-27-miami"
# [3] "2014-05-12-ubc"
# ...E falando em “dois”…
Para finalizar esse tutorial, vou criar uma função simples que retorna
o número de estrelas que cada usuário tem. Nessa tarefa temos que iterar
em dois objetos: ghr e os nomes de seus usuários.
about <- function(user, name) {
stars <- map_dbl(user, ~.x$stargazers_count) %>% sum()
message(name, " has ", stars, " stars!")
}
map2(ghr, names(ghr), about)
# gaborcsardi has 289 stars!
# jennybc has 190 stars!
# jtleek has 4910 stars!
# juliasilge has 308 stars!
# leeper has 66 stars!
# masalmon has 47 stars!Em about() pegamos a soma da contagem de star gazers de cara repo de um
usuário (usando map_dbl(), claro) e depois soltamos a mensagem com o nome.
Para fazer isso para cada usuário de ghr, usamos a prima mais próxima de
map(): map2().
Essa função é análoga a map(), mas itera em duas listas ao invés de somente
usa (note que para fórmulas usamos .x no lugar dos elementos da primeira lista
e .y no lugar dos elementos da segunda). E agora que você já entende os
membros mais importantes da família map(), aqui está uma lista de todos os
outros que você já pode começar a usar:
map2_xxx()(análoga amap_xxx())pmap()(com a qual você pode iterar em quantos elementos forem necessários)lmap()(para mapear com funções que recebem e retornam listas)imap()(para iterar em uma lista e seus nomes, assim como acabamos de fazer)map_at()/map_if()(funções que permitem com que você filtre quais elementos serão mapeados)
Palavras finais
Esse não foi um post pequeno, mas eu sinto que não poderia ter feito ele em menos palavras. Mapeamento é um conceito complicado e demorou muito tempo para que eu entendesse o pouco que eu sei.
O pacote purrr é realmente uma ferramenta incrível (na minha opinião, a mais
conveniente e bonita da linguagem R) e é justo dizer que a map() é grande
parte do motivo… Mas ela não é a única família de funções no pacote!
No próximo post falaremos sobre algumas outras funções do purrr:
reduce(), flatten(), invoke(), modify(), possibly() e keep().
Enquanto isso, dê uma olhada no meu github,
no de Jennifer Bryan (autora do repurrrsive)
e no de Hadley Wickham (autor do purrr e outros
pacotes incríveis de R).