Web scraping distribuído
Caso você já tenha se aventurado no mundo do web scraping, é provável que tenha se deparado com um grande problema: volume. Muitas vezes, antes fazer uma análise, precisamos scrapear um número colossal de páginas até que tenhamos dados o suficiente para a nossa tarefa, número esse que chega a ser proibitivo a ponto de não conseguirmos fazer aquilo que queremos.
Neste post vou explicar duas técnicas para aumentar em dezenas de vezes a velocidade dos seus scrapers de forma que você nunca mais precise de preocupar com a quantidade de dados necessária para uma análise.
Scrapers sequenciais
Um scraper sequencial é qualquer scraper que baixe uma página por vez, ou seja, que varra as páginas em sequência baixando uma a uma. Como veremos na seção a seguir isso não é muito eficiente, mas é mesmo assim o que a maioria de nós faz.
Nota: Nos exemplos que darei daqui em diante estarei baixando uma lista de
1441 artigos da Wikipédia obtida com o pacote WikipediR. Se você quiser
reproduzir os meus achados, disponibilizei um arquivo com o código completo em
um Gist
Veja mais ou menos como funcionaria para baixar um link da Wikipédia por vez:
# Função para baixar uma página da Wikipédia
download_wiki <- function(url, path) {
# Converter um URL em um nome de arquivo
file <- url %>%
utils::URLdecode() %>%
stringr::str_extract("(?<=/)[^/]+$") %>%
stringr::str_replace_all("[:punct:]", "") %>%
stringr::str_to_lower() %>%
stringr::str_c(normalizePath(path), "/", ., ".html")
# Salvar a página no disco
httr::GET(url, httr::write_disk(file, TRUE))
return(file)
}
# Baixar arquivos sequencialmente
files <- purrr::map_chr(links, download_wiki, "~/Desktop/Wiki")Nada muito complexo até aí. Com a purrr::map_chr() itero com facilidade nos
links e os baixo sequencialmente (se você quiser saber mais sobre a função
map() veja este post). O código acima
demorou mais ou menos 5 minutos para executar na minha máquina.
Scrapers em paralelo
Uma das formas mais simples de aumentar a eficiência de um web scraper é através de paralelização. Um fato que nem todos sabem é que praticamente qualquer scraper passa a maior parte do tempo esperando respostas do servidor; seja para carregar uma nova página ou seja para baixar a página em questão, ficar esperando é o que o seu scraper provavelmente mais faz.
Isso quer dizer que seu computador poderia ter, em qualquer dado momento, múltiplos scrapers rodando simultaneamente sem perder eficiência! Enquanto o processador está salvando no disco os resultados de um scraper, é perfeitamente possível ter muitos outros ativos e esperando uma resposta do servidor.
No exemplo de código abaixo uso uma função muito simples para paralelizar a
execução do scraper. parallel::mcmapply() (multicore mapply()) é análoga a
map(), com a diferença de que ela instancia as chamadas para a função
download_wiki() em múltiplos threads de execução, tirando vantagem do fato
de que cada instância fica parada a maior parte do tempo.
# Criar uma versão empacotada de download_wiki()
download_wiki_ <- purrr::partial(
download_wiki, path = "~/Desktop/Wiki", .first = FALSE)
# Baixar arquivos em paralelo
files <- parallel::mcmapply(
download_wiki_, links, SIMPLIFY = TRUE, mc.cores = 4)No código acima, crio uma versão pré-preenchida de download_wiki() para não
precisar lidar com argumentos constantes na chamada para parallel::mcmapply(),
mas depois disso a única coisa que preciso fazer é especificar o número de
cores disponíveis no meu computador para que o pacote parallel faça a sua
magia. Desta forma, com uma chamada marginalmente mais complexa, consegui
baixar os mesmos arquivos em meros 1.2 minutos.
Scrapers distribuídos
Para o nosso grand finale temos um pequeno salto de dificuldade. Agora que somos capazes de usar todo o potencial do nosso computador, a única forma de fazer scraping mais rápido é usando mais computadores.
Isso parece loucura, mas usando máquinas virtuais da Amazon ou da Google essa é na verdade uma tarefa bastante simples! Podemos criar algumas instâncias virtuais e enviar os links para que elas os baixem, distribuindo o download entre várias máquinas.
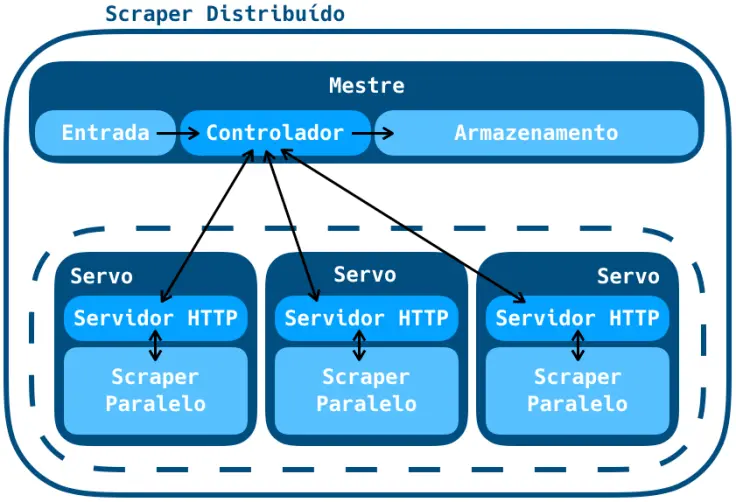
Para permitir que uma máquina virtual receba o comando de download, criei um pequeno servidor HTTP em cada uma, assim elas ficarão esperando por uma chamada POST contendo os URLs a serem baixados.
# Trecho do código em python do servidor que lida com POSTs
def do_POST(self):
content_length = int(self.headers['Content-Length'])
post_data = self.rfile.read(content_length)
call(["Rscript", "~/script.R", post_data])Como pode-se ver no código acima, a única coisa que o servidor faz é
coletar os dados enviados pelo post e redirecioná-los para o script
script.R. Lá o R coleta os links vindos de post_data e os baixa
(usando, é claro, parallel::mcmapply).
#!/usr/bin/env Rscript
args = commandArgs(trailingOnly=TRUE)
# Tratar o pacote de dados enviado no POST
links <- stringr::str_split(args[1], " ")[[1]]Acima temos a única diferença no código em R (que agora se encontra nas máquinas
virtuais): o tratamento necessário em script.R dos dados trazidos pela chamada
POST.
O último passo é, em nossa máquina local, quebrar a lista de links em um pacote para cada máquina serva; assim que as máquinas receberem esses links via HTTP elas começarão, distribuidamente, a baixá-los em paralelo.
# Quebrar os links de acordo com o número de servos
num_workers <- 3
links_split <- links %>%
split(., ceiling(seq_along(.)/(length(.)/num_workers))) %>%
purrr::map(stringr::str_c, collapse = " ")
# Dados do endpoint
workers <- "localhost" # AQUI VÃO OS IPS DOS SERVOS
endpoints <- stringr::str_c("http://", workers, ":8000")
# Chamar todos os servos mas não esperar por eles
for (i in seq_len(num_workers)) {
command <- paste0("curl -d '", links_split[[i]], "' ", endpoints[i])
system(command, wait = FALSE)
}Usando 3 máquinas virtuais de 4 cores cada no Google Cloud Platform, o download das 1400 páginas demorou meros 34 segundos. Isso é uma melhora de aproximadamente 10 vezes na performance em relação à execução sequencial!
Conclusão
Como vimos nos exemplos acima, scrapers são por padrão processos lentos e ineficientes. Usando uma arquitetura razoavelmente simples distribuída e paralela podemos aumentar em até uma ordem de grandeza a eficiência de um scraper sem nem pensar sobre o seu código! Na prática, podemos aumentar e diminuir o quanto quisermos o número de servos ou de cores em cada servo, permitindo que qualquer scraper possa virar uma máquina incrível de coleta de dados.
Caso você tenha se interessado pelo conteúdo abordado nesse post, eu e o pessoal da Curso-R vamos dar no dia 10/03/2018 um workshop em São Paulos sobre web scraping com R. Lá você vai ter a oportunidade de aprender, do zero, como fazer bons web scrapers em R além de muitas dicas como a desse post para tornar seus scrapers ainda melhores.