The magic of purrr
Have you ever heard about an R package called purrr? It’s described as a functional
programming toolkit for the R language and allows us to do truly amazing things. If you’ve
never heard of purrr or even if you have but don’t know its full potential, this post is
meant for you.
Sorry for being honest
If you wanted make R more concise, what would you change about it? A good first attempt might revolve around simplifying “function composition” (the act of applying one function to the result of another). Take a look at this awful example:
car_data <-
transform(aggregate(. ~ cyl,
data = subset(mtcars, hp > 100),
FUN = function(x) round(mean(x, 2))),
kpl = mpg*0.4251)If we don’t want to save intermediate results, composing multiple functions becomes super important. But the approach shown above makes it very hard to understand what is happening and in what order (for the math nerds reading this, it’s the equivalent of writing instead of ). In R, the solution to this problem comes in the form of the “pipe”, an operator that allows us to place the first function before the second rather than inside it:
car_data <-
mtcars %>%
subset(hp > 100) %>%
aggregate(. ~ cyl, data = ., FUN = . %>% mean %>% round(2)) %>%
transform(kpl = mpg %>% multiply_by(0.4251))But what else would you change about R? Well, the next obvious improvement are loops…
Lists of lists
Before we start the demonstration, you’ll need a handful of packages. Install them by executing the code below:
install.packages(c("devtools", "purrrr"))
devtools::install_github("jennybc/repurrrsive")
library(purrr)Now that we have everything up and running, let’s get to know the star of this
tutorial! gh_repos is a massive multi-level list that might scare even the most
seasoned R programmers. I’ll be renaming gh_repos to ghr for simplicity:
ghr <- repurrrsive::gh_reposFortunately, its structure is simple enough so that we can use it for educational
purposes. ghr’s first level is made up of 6 lists, each of them representing
a GitHub user. Each of these lists is made up of around 30 smaller lists
representing that user’s GitHub repositories. Each repository list has 60+ fields
with information about the repo; one of these fields is also a list and contains
login data belonging to that repo’s owner.
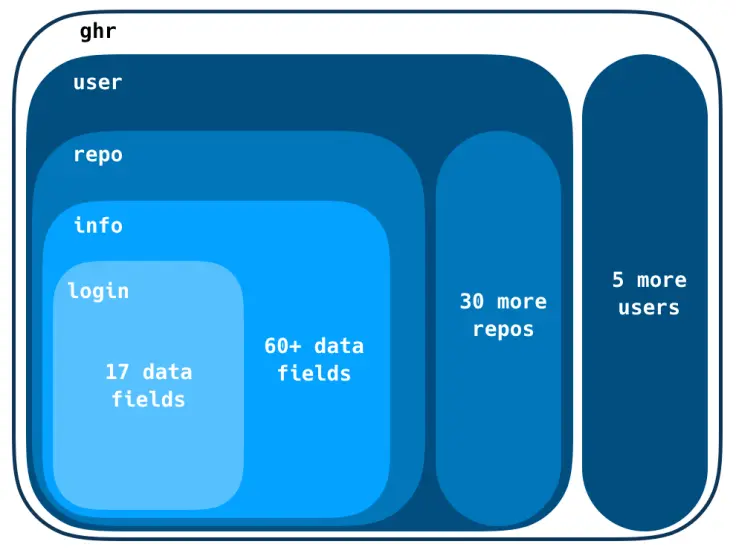
This doesn’t look very straightforward, but we’ll review this structure as we go along.
As a list refresher, let’s see how many repositories does the first user in ghr have:
length(ghr[[1]])
# [1] 30In this short statement we’re selecting the first element of the first level of the list
(ghr[[1]]) or, in other words, we’re choosing the first user. By applying length()
to this user, we can see how many elements it has, resulting in the number of repos
owned by that them. More generally, if we wanted to see how many information fields are
there for the 3rd repo owned by the 1st user (or the length of the third element of the
second level associated with the first element of the first level), we’d want to run
length(ghr[[1]][[3]]).
One-line loops
Now that you remember how lists work in R, an obvious step up in difficulty is finding out
how many repository each user has. This can be solved with the good old for loop,
applying length() to each element of the first level of ghr:
lengths <- c()
for (i in seq_along(ghr)) {
lengths <- c(lengths, length(ghr[[i]]))
}
lengths
# [1] 30 30 30 26 30 30But come on, there has got to be a simpler way! We are only iterating over a list,
why would we need i, c(), seq_along(), or even lengths? This is where map()
comes in, the purrr package’s workhorse. map() is a loop abstraction, allowing us
to iterate over the elements of the list and not some auxiliary variable. In other words
it applies a function to every element of a list.
map(ghr, length)
# [[1]]
# [1] 30
#
# [[2]]
# [1] 30
#
# [[3]]
# [1] 30
#
# [[4]]
# [1] 26
#
# [[5]]
# [1] 30
#
# [[6]]
# [1] 30I mean, we used less lines of code, but what is happening to that output? map() is
a very general function, so it always returns lists (so that it doesn’t have to
worry about the type of the output). But map() has many sister functions, map_xxx()
(map_dbl(), map_chr(), map_lgl(), …), which are able to flatten out the output
if you already know what type it’s gonna have. In our case, we want a vector of doubles,
so we use map_dbl():
map_dbl(ghr, length)
# [1] 30 30 30 26 30 30Did you see that?! That’s 21 characters long and did exactly the same thing as that ugly loop up there!
Form(ula) and function
Now that you’ve seen the basic building block of purrr, I’ll introduce you to
anonymous functions, another great feature of purrr. These are functions you can
define inside a map() without having to give it a name. They come in two flavors:
formulas and functions.
Formulas are preceded by a tilde “~” and you can’t control what their arguments are named. Functions on the other hand are, well, regular R functions. First let’s see how formulas work:
map_dbl(ghr, ~length(.x))
# [1] 30 30 30 26 30 30Formulas allow us to pass arguments to the function being mapped. Remember how
we were taking the length of every sub-list of ghr? If we use the tilde
notation, we can explicitly access that element and place it wherever we want
inside the function call, but it’s name is going to be .x no matter what.
map(1:3, ~runif(2, max = .x))
# [[1]]
# [1] 0.2512402 0.4499058
#
# [[2]]
# [1] 1.767479 1.600513
#
# [[3]]
# [1] 2.367293 1.263795In the example above we have to use the tilde notation because, if we hadn’t,
the vector 1:3 would end up being used as the first argument of runif(). And
speaking of arguments, map() conveniently allows you to send any fixed
arguments you want at the end of the call (note how this time 1:3 is used
automatically as the first argument):
map(1:3, runif, min = 3, max = 6)
# [[1]]
# [1] 3.902211
#
# [[2]]
# [1] 4.511896 4.405196
#
# [[3]]
# [1] 5.498137 3.940454 5.413348And, last but not least, functions. These are very similar to formulas, whereas here you can name arguments however you like (but as a drawback you have to define the function in a very verbose way):
map(1:3, function(n) { runif(n, min = 3, max = 6) })
# [[1]]
# [1] 4.54061
#
# [[2]]
# [1] 3.557612 4.022569
#
# [[3]]
# [1] 3.369300 4.109919 4.095583Mapping the map
As you might have already figured out, we can also nest map() calls! This is
useful when accessing deeper levels of a list (like when we talked about
length(ghr[[1]][[3]])). Let’s try to see how many information fields each
repo of each user has:
map(ghr, ~map(.x, length))
# [[1]]
# [[1]][[1]]
# [1] 68
#
# [[1]][[2]]
# [1] 68
#
# [[1]][[3]]
# [1] 68
#
# [[1]][[4]]
# [1] 68
#
# ...
map(ghr, ~map_dbl(.x, length))
# [[1]]
# [1] 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68
# [20] 68 68 68 68 68 68 68 68 68 68 68
#
# [[2]]
# [1] 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68 68
# [20] 68 68 68 68 68 68 68 68 68 68 68
#
# ...The first command above outputs a very long list of lists, but that’s just
because the innermost map() returns a list for each repo and then the
outermost map() wraps all of that in another list. For a more
straightforward output, using map_dbl() on the innermost call allows us
to output a single vector for each user.
But these fields contain precious information. So far our list has been
completely nameless, meaning that each user list and each repo list
are not marked with the names of the users and the repos. Let’s see
if we can find the names of the users in the login field of the
$owner list of each repo (note the use of map_chr(); this is the
character equivalent of map_dbl()):
map(ghr, function(user) {
map_chr(user, ~.x$owner$login)
})
# [[1]]
# [1] "gaborcsardi" "gaborcsardi" "gaborcsardi" "gaborcsardi"
# [5] "gaborcsardi" "gaborcsardi" "gaborcsardi" "gaborcsardi"
# ...
#
# [[2]]
# [1] "jennybc" "jennybc" "jennybc" "jennybc" "jennybc"
# [6] "jennybc" "jennybc" "jennybc" "jennybc" "jennybc"
# ...
#
# ...
map(ghr, function(user) {
user %>% map_chr(~.x$owner$login)
})
# ...
map(ghr, ~map_chr(.x, ~.x$owner$login))
# ...All three statements output the exact same thing, but the first one is
easier to understand. For each user, we map over their repos and access
the $owner$login element. The second one shows us that it is possible to
map a pipe. The third one on the other hand, condenses everything to a
maximum (note how we use .x twice; the first time comes from the map()
and stands for each user, while the second time comes from map_chr()
and stands for each repo).
But all statements suffer from the repetition problem in their outputs given
the fact that we’re doing the same thing for absolutely every repo available.
Since we just need this information once for every user, we can employ the
good old [1] to get only the first element of the vector returned by
map_chr() and then use another map_chr() so we don’t have to deal
with weird lists:
map_chr(ghr, ~map_chr(.x, ~.x$owner$login)[1])
# [1] "gaborcsardi" "jennybc" "jtleek" "juliasilge"
# [5] "leeper" "masalmon"Piping the map
In the section above we mapped a pipe, now we’ll pipe a map. This is
should be very straightforward given the last bit of code, but
we’ll use mapping to get the logins of the users, then set_names()
to name the user lists according to their logins and finally pluck()
the list of repos belonging to “jennybc” (note the dot in set_names();
it stands for the results incoming from the line above, we’re using
it as the second argument for the function):
ghr %>%
map_chr(~map_chr(.x, ~.x$owner$login)[1]) %>%
set_names(ghr, .) %>%
pluck("jennybc")
# ...The output of this command was omitted, but using pluck() selected
only the element of ghr named as “jennybc” (this function works just
like [[]], so we could have also used 2 since Jenny’s list is the
second one of the first level).
Turtles all the way down
Now that we know how to name the first level of our structure, how about we also name the repos? For this we have to go a level deeper and set the names there too:
ghr %>%
map(function(user) {
user %>%
set_names(map(., ~.x$name))
}) %>%
pluck("jennybc", "eigencoder")
# ...
ghr %>%
map(~set_names(.x, map(.x, ~.x$name))) %>%
pluck("jennybc", "eigencoder")
# ...Both sequences output the same thing (omitted), but the second one is much
more concise. Here we’re mapping over users, setting the name for each
repo based on that repo’s $name element, and then plucking Jenny’s
eigencoder repo (this would be equivalent to [[2]][[30]]).
Hole in two
A nice thing about coding is trying to write the same thing in as few
characters as possible (called code golf). Before we assign both user and
repo names to ghr, lets make the user-naming process a little bit nicer:
set_names(ghr, map_chr(ghr, ~map_chr(.x, ~.x$owner$login)[1]))
set_names(ghr, map(ghr, ~map(.x, ~.x$owner$login)[[1]]))
set_names(ghr, map(ghr, ~.x[[1]]$owner$login))All three statements do exactly the same thing, the first of which we’ve
already seen. The second statement takes into advantage the fact that
set_names() doesn’t have to receive a vector as argument, a list will
do just fine. The third one reverses a bit our idea of getting the login
from every repo and then selecting the first by getting the login from
only the first repo.
Now that we have the shortest way possible to assign the names to ghr,
here is what I call a hole in two:
ghr <- ghr %>%
set_names(map(., ~.x[[1]]$owner$login)) %>%
map(~set_names(.x, map(.x, ~.x$name)))
> names(ghr)
# [1] "gaborcsardi" "jennybc" "jtleek" "juliasilge"
# [5] "leeper" "masalmon"
> names(ghr$jennybc)
# [1] "2013-11_sfu"
# [2] "2014-01-27-miami"
# [3] "2014-05-12-ubc"
# ...And peaking of “two”…
As a wrap up for this lesson, I’ll create a simple function that will
output the number of stars each user has. In this task, we have to
iterate over two objects: ghr and the names of the users.
about <- function(user, name) {
stars <- map_dbl(user, ~.x$stargazers_count) %>% sum()
message(name, " has ", stars, " stars!")
}
map2(ghr, names(ghr), about)
# gaborcsardi has 289 stars!
# jennybc has 190 stars!
# jtleek has 4910 stars!
# juliasilge has 308 stars!
# leeper has 66 stars!
# masalmon has 47 stars!In about() we get the sum of star gazers for each repo of a user (using
a map_dbl() of course) and then we simply output the message with the name.
To do this to every user in ghr, we use map()’s closest cousin: map2().
This function is analogous to map() but iterates over two lists instead of
only one (note that for formulas we’d use .x for the elements of the first
list and .y for the elements of the second). And now that you understand the
most important members of the map() family, here’s a list of the other ones
that you can start using right away:
map2_xxx()(analogous tomap_xxx())pmap()(with which you can map over however many elements you want)lmap()(for mapping with functions that take and return lists)imap()(for mapping over a list and its names, just like we did above)map_at()/map_if()(functions that allow you to filter which elements get mapped)
Wrap up
This wasn’t a small post, but I feel like I couldn’t have done it in less words. Mapping is a very difficult concept and it took me a lot of time to understand the very little I know.
The purrr package is a truly amazing tool (in my opinion it’s the most
convenient and beautiful element of the R language) and it’s fair
to say that map() is a big part of it… But it isn’t the only family
of functions in the package!
In the next post we’ll talk about some of the other functions of purrr:
reduce(), flatten(), invoke(), modify(), possibly() and keep().
In the mean time, check out my github,
Jennifer Bryan’s (the author of repurrrsive)
and Hadley Wickham’s (the author of purrr and
many other amazing R packages).